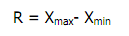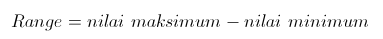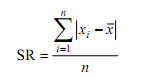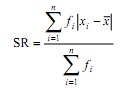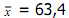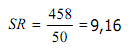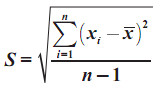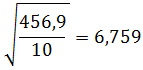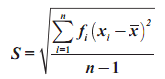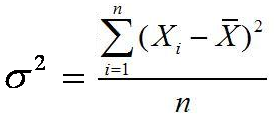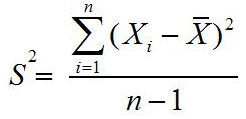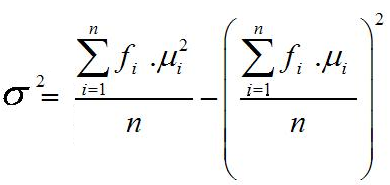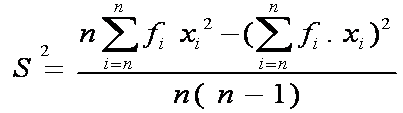Bab 2
Cara penyajian data
Ada dua cara penyajian data yang sering dilakukan, yaitu
a) daftar atau tabel,
b) grafik atau diagram.
1. Penyajian Data dalam Bentuk Tabel
Misalkan, hasil ulangan Bahasa Indonesia 37 siswa kelas XI SMA 3 disajikan dalam tabel di samping. Penyajian data pada Tabel 1.1 dinamakan penyajian data sederhana. Dari tabel 1.1, Anda dapat menentukan banyak siswa yang mendapat nilai 9, yaitu sebanyak 7 orang. Berapa orang siswa yang mendapat nilai 5? Nilai berapakah yang paling banyak diperoleh siswa? Jika data hasil ulangan bahasa Indonesia itu disajikan dengan cara mengelompokkan data nilai siswa, diperoleh tabel frekuensi berkelompok seperti pada Tabel 1.2. Tabel 1.2 dinamakan Tabel Distribusi Frekuensi..png)
.png)
a) daftar atau tabel,
b) grafik atau diagram.
1. Penyajian Data dalam Bentuk Tabel
Misalkan, hasil ulangan Bahasa Indonesia 37 siswa kelas XI SMA 3 disajikan dalam tabel di samping. Penyajian data pada Tabel 1.1 dinamakan penyajian data sederhana. Dari tabel 1.1, Anda dapat menentukan banyak siswa yang mendapat nilai 9, yaitu sebanyak 7 orang. Berapa orang siswa yang mendapat nilai 5? Nilai berapakah yang paling banyak diperoleh siswa? Jika data hasil ulangan bahasa Indonesia itu disajikan dengan cara mengelompokkan data nilai siswa, diperoleh tabel frekuensi berkelompok seperti pada Tabel 1.2. Tabel 1.2 dinamakan Tabel Distribusi Frekuensi.


2. Penyajian Data dalam Bentuk Diagram
Kerapkali data yang disajikan dalam bentuk tabel sulit untuk dipahami. Lain halnya jika data tersebut disajikan dalam bentuk diagram maka Anda akan dapat lebih cepat memahami data itu. Diagram adalah gambar yang menyajikan data secara visual yang biasanya berasal dari tabel yang telah dibuat. Meskipun demikian, diagram masih memiliki kelemahan, yaitu pada umumnya diagram tidak dapat memberikan gambaran yang lebih detail.
a. Diagram Batang
Diagram batang biasanya digunakan untuk menggambarkan data diskrit (data cacahan). Diagram batang adalah bentuk penyajian data statistik dalam bentuk batang yang dicatat dalam interval tertentu pada bidang cartesius. Ada dua jenis diagram batang, yaitu
1) diagram batang vertikal, dan
2) diagram batang horizontal.
b. Diagram Garis
Pernahkah Anda melihat grafik nilai tukar dolar terhadap rupiah atau pergerakan saham di TV? Grafik yang seperti itu disebut diagram garis. Diagram garis biasanya digunakan untuk menggambarkan data tentang m keadaan yang berkesinambungan (sekumpulan data kontinu). Misalnya, jumlah penduduk setiap tahun, perkembangan berat badan bayi setiap bulan, dan suhu badan pasien setiap jam.Seperti halnya diagram batang, diagram garis pun memerlukan sistem sumbu datar (horizontal) dan sumbu tegak (vertikal) yang saling berpotongan tegak lurus. Sumbu mendatar biasanya menyatakan jenis data, misalnya waktu dan berat. Adapun sumbu tegaknya menyatakan frekuensi data. Langkah-langkah yang dilakukan untuk membuat diagram garis adalah sebagai berikut.
1) Buatlah suatu koordinat (berbentuk bilangan) dengan sumbu mendatar menunjukkan waktu dan sumbu tegak menunjukkan data pengamatan.
2) Gambarlah titik koordinat yang menunjukkan data pengamatan pada waktu t.
3) Secara berurutan sesuai dengan waktu, hubungkan titiktitik koordinat tersebut dengan garis lurus.
Pernahkah Anda melihat grafik nilai tukar dolar terhadap rupiah atau pergerakan saham di TV? Grafik yang seperti itu disebut diagram garis. Diagram garis biasanya digunakan untuk menggambarkan data tentang m keadaan yang berkesinambungan (sekumpulan data kontinu). Misalnya, jumlah penduduk setiap tahun, perkembangan berat badan bayi setiap bulan, dan suhu badan pasien setiap jam.Seperti halnya diagram batang, diagram garis pun memerlukan sistem sumbu datar (horizontal) dan sumbu tegak (vertikal) yang saling berpotongan tegak lurus. Sumbu mendatar biasanya menyatakan jenis data, misalnya waktu dan berat. Adapun sumbu tegaknya menyatakan frekuensi data. Langkah-langkah yang dilakukan untuk membuat diagram garis adalah sebagai berikut.
1) Buatlah suatu koordinat (berbentuk bilangan) dengan sumbu mendatar menunjukkan waktu dan sumbu tegak menunjukkan data pengamatan.
2) Gambarlah titik koordinat yang menunjukkan data pengamatan pada waktu t.
3) Secara berurutan sesuai dengan waktu, hubungkan titiktitik koordinat tersebut dengan garis lurus.
c. Diagram Lingkaran
Untuk mengetahui perbandingan suatu data terhadap keseluruhan, suatu data lebih tepat disajikan dalam bentuk diagram lingkaran. Diagram lingkaran adalah bentuk penyajian data statistika dalam bentuk lingkaran yang dibagi menjadi beberapa juring lingkaran. Langkah-langkah untuk membuat diagram lingkaran adalah sebagai berikut.
1. Buatlah sebuah lingkaran pada kertas.
2. Bagilah lingkaran tersebut menjadi beberapa juring lingkaran untuk menggambarkan kategori yang datanya telah diubah ke dalam derajat.
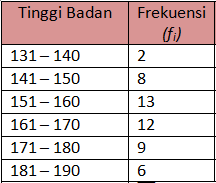
3. Tabel Distribusi Frekuensi, Frekuensi Relatif dan Kumulatif, Histogram, Poligon Frekuensi, dan Ogive
a. Tabel Distribusi FrekuensiData yang berukuran besar (n > 30) lebih tepat disajikan dalam tabel distribusi frekuensi, yaitu cara penyajian data yang datanya disusun dalam kelas-kelas tertentu. Langkah-langkah penyusunan tabel distribusi frekuensi adalah sebagai berikut.
• Langkah ke-2 menentukan banyak interval (K) dengan rumus "Sturgess" yaitu: K= 1 + 3,3 log n dengan n adalah banyak data. Banyak kelas harus merupakan bilangan bulat positif hasil pembulatan.
• Langkah ke-3 menentukan panjang interval kelas (I) dengan menggunakan rumus:
Untuk mengetahui perbandingan suatu data terhadap keseluruhan, suatu data lebih tepat disajikan dalam bentuk diagram lingkaran. Diagram lingkaran adalah bentuk penyajian data statistika dalam bentuk lingkaran yang dibagi menjadi beberapa juring lingkaran. Langkah-langkah untuk membuat diagram lingkaran adalah sebagai berikut.
1. Buatlah sebuah lingkaran pada kertas.
2. Bagilah lingkaran tersebut menjadi beberapa juring lingkaran untuk menggambarkan kategori yang datanya telah diubah ke dalam derajat.
3. Tabel Distribusi Frekuensi, Frekuensi Relatif dan Kumulatif, Histogram, Poligon Frekuensi, dan Ogive
a. Tabel Distribusi FrekuensiData yang berukuran besar (n > 30) lebih tepat disajikan dalam tabel distribusi frekuensi, yaitu cara penyajian data yang datanya disusun dalam kelas-kelas tertentu. Langkah-langkah penyusunan tabel distribusi frekuensi adalah sebagai berikut.
• Langkah ke-2 menentukan banyak interval (K) dengan rumus "Sturgess" yaitu: K= 1 + 3,3 log n dengan n adalah banyak data. Banyak kelas harus merupakan bilangan bulat positif hasil pembulatan.
• Langkah ke-3 menentukan panjang interval kelas (I) dengan menggunakan rumus:

• Langkah ke-4 menentukan batas-batas kelas. Data terkecil harus merupakan batas bawah interval kelas pertama atau data terbesar adalah batas atas interval kelas terakhir. • Langkah ke-5 memasukkan data ke dalam kelas-kelas yang sesuai dan menentukan nilai frekuensi setiap kelas dengan sistem turus. • Menuliskan turus-turus dalambilangan yang bersesuaian dengan banyak turus.
b. Frekuensi Relatif dan Kumulatif
Frekuensi yang dimiliki setiap kelas pada tabel distribusi frekuensi bersifat mutlak. Adapun frekuensi relatif dari suatu data adalah dengan membandingkan frekuensi pada interval kelas itu dengan banyak data dinyatakan dalam persen. Contoh: interval frekuensi kelas adalah 20. Total data seluruh interval kelas = 80 maka frekuensi relatif kelas ini adalah

Frekuensi relatif dirumuskan sebagai berikut.
b. Frekuensi Relatif dan Kumulatif
Frekuensi yang dimiliki setiap kelas pada tabel distribusi frekuensi bersifat mutlak. Adapun frekuensi relatif dari suatu data adalah dengan membandingkan frekuensi pada interval kelas itu dengan banyak data dinyatakan dalam persen. Contoh: interval frekuensi kelas adalah 20. Total data seluruh interval kelas = 80 maka frekuensi relatif kelas ini adalah
Frekuensi relatif dirumuskan sebagai berikut.

Frekuensi kumulatif kelas ke-k adalah jumlah frekuensi pada kelas yang dimaksud dengan frekuensi kelas-kelas sebelumnya. Ada dua macam frekuensi kumulatif, yaitu
1) frekuensi kumulatif "kurang dari" ("kurang dari" diambil terhadap tepi atas kelas)
2) frekuensi kumulatif "lebih dari" ("lebih dari" diambil terhadap tepi bawah kelas).
1) frekuensi kumulatif "kurang dari" ("kurang dari" diambil terhadap tepi atas kelas)
2) frekuensi kumulatif "lebih dari" ("lebih dari" diambil terhadap tepi bawah kelas).

c. Histogram dan Poligon Frekuensi
Histogram merupakan diagram frekuensi bertangga yang bentuknya seperti diagram batang. Batang yang berdekatan harus berimpit. Untuk pembuatan histogram, pada setiap interval kelas diperlukan tepi-tepi kelas. Tepi-tepi kelas ini digunakan unntuk menentukan titik tengah kelas yang dapat ditulis sebagai berikut.
Histogram merupakan diagram frekuensi bertangga yang bentuknya seperti diagram batang. Batang yang berdekatan harus berimpit. Untuk pembuatan histogram, pada setiap interval kelas diperlukan tepi-tepi kelas. Tepi-tepi kelas ini digunakan unntuk menentukan titik tengah kelas yang dapat ditulis sebagai berikut.
Poligon frekuensi dapat dibuat dengan menghubungkan titik-titik tengah setiap puncak persegipanjang dari histogram secara berurutan. Agar poligon "tertutup" maka sebelum kelas paling bawah dan setelah kelas paling atas, masing-masing ditambah satu kelas.
d. Ogive (Ogif)
Grafik yang menunjukkan frekuensi kumulatif kurang dari atau frekuensi kumulatif lebih dari dinamakan poligon kumulatif. Untuk populasi yang besar, poligon mempunyai banyak ruas garis patah yang menyerupai kurva sehingga poligon frekuensi kumulatif dibuat mulus, yang hasilnya disebut ogif. Ada dua macam ogif, yaitu sebagai berikut.
a. Ogif dari frekuensi kumulatif kurang dari disebut ogif positif.
b. Ogif dari frekuensi kumulatif lebih dari disebut ogif negatif.
diposting oleh Unknown @ 21.07
0 Komentar
![]()



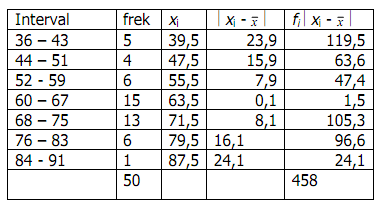
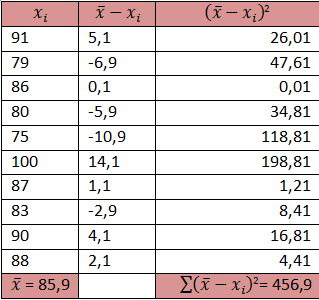
 Ukuran penyebaran (Measures of Dispersion) atau ukuran keragaman pengamatan dari nilai rata-ratanya disebut simpangan (deviation/dispersi). Terdapat beberapa ukuran untuk menentukan dispersi data pengamatan, seperti jangkauan/rentang (range), simpangan kuartil (quartile deviation), simpangan rata-rata (mean deviation), dan simpangan baku (standard deviation).
Ukuran penyebaran (Measures of Dispersion) atau ukuran keragaman pengamatan dari nilai rata-ratanya disebut simpangan (deviation/dispersi). Terdapat beberapa ukuran untuk menentukan dispersi data pengamatan, seperti jangkauan/rentang (range), simpangan kuartil (quartile deviation), simpangan rata-rata (mean deviation), dan simpangan baku (standard deviation).